

최신연구
[한욱신 교수] Bring My Cup! Personalizing Vision-Language-Action Models with Visual Attentive Prompting
- 등록일2026.05.27
- 조회수38
-

교수한욱신
[연구의 필요성]
- 가정·사무실·병원 등 실제 생활 환경에서 로봇이 유용하게 동작하려면 “컵을 가져와”와 같은 일반적인 범주 수준의 명령뿐 아니라, “내 컵을 가져와”처럼 특정 사용자의 물건을 정확히 구분하고 조작할 수 있어야 한다. 그러나 기존 시각-언어-행동(Vision-Language-Action, VLA) 모델은 대규모 로봇 데이터로 학습되어 일반적인 물체 범주는 잘 이해하지만, 학습 중 본 적 없는 개인 물체나 사용자별 지칭 표현에는 취약하다. 예를 들어 여러 개의 컵이 함께 놓여 있을 때, 기존 모델은 “내 컵”을 사용자의 특정 컵이 아니라 단순히 “컵”이라는 범주로 해석하여 시각적으로 유사한 다른 컵을 집거나 옮기는 실패를 보인다.
이 문제는 언어 설명을 더 자세히 제공하는 것만으로 해결되기 어렵다. 개인 물체를 구별하는 핵심 단서는 표면 무늬, 손잡이 모양, 작은 장식, 마모 흔적처럼 말로 완전하게 표현하기 어려운 미세한 시각적 특징에 있기 때문이다. 또한 실제 환경에서는 사용자마다 새로운 물체가 계속 추가되므로, 물체별로 모델을 다시 학습하는 방식은 데이터 수집과 계산 비용 측면에서 비현실적이다. 따라서 소수의 참조 사진만으로 사용자의 특정 물체를 찾아내고, 기존 모델의 파라미터를 수정하지 않으면서도 해당 물체를 안정적으로 조작하게 만드는 개인화 조작 기술이 필요하다.
[포스텍이 가진 고유의 기술]
- 본 연구진은 개인 물체 조작 문제를 해결하기 위해 Visual Attentive Prompting(VAP, 시각 주의 유도 방식)을 제안하였다. VAP는 기존 시각-언어-행동 모델의 파라미터를 수정하거나 물체별로 재학습하지 않고, 입력 단계에서 시각 단서와 언어 명령을 함께 변환하여 고정된 모델이 사용자의 특정 물체를 조작하도록 유도하는 training-free 개인화 기술이다.
(1) 참조 사진 기반 시각 기억과 개인 물체 식별: VAP는 사용자가 제공한 소수의 물체 사진을 시각 기억으로 저장한다. 로봇이 현재 장면을 관측하면, 먼저 명령문에서 “내 컵”과 같은 표현으로부터 일반 물체 범주를 추출하고, 개방형 어휘 객체 검출기를 이용해 해당 범주의 후보 물체들을 찾는다. 이후 시각 특징 벡터를 사용하여 각 후보 물체와 참조 사진들을 비교하고, 여러 참조 사진이 가장 일관되게 지지하는 후보를 개인 물체로 선택한다. 선택된 후보는 픽셀 단위 마스크로 정교하게 분할되며, 이후 추적 모듈을 통해 로봇 팔이나 집게가 물체를 일시적으로 가리더라도 같은 물체를 계속 따라갈 수 있도록 시간에 따라 갱신된다.
(2) 시각-언어 결합 지시를 통한 모델 제어: VAP는 선택된 개인 물체 영역 위에 반투명 색상 표시를 입혀 모델이 어느 물체에 주의해야 하는지 명시적으로 알려준다. 동시에 원래 명령문도 “내 컵을 집어라”에서 “빨간색 컵을 집어라”처럼 시각 표시와 일치하는 표현으로 다시 작성한다.즉, 시각 표시는 “어디를 볼지”를 알려주고, 바뀐 명령문은 “무엇을 조작할지”를 언어적으로 고정한다. 이 두 요소가 함께 작동함으로써, 기존 모델이 보유한 일반 물체 조작 능력을 사용자의 특정 물체에 적용할 수 있게 된다.
[연구의 의미]
- 본 연구는 시각-언어-행동 모델의 개인화 문제를 “사용자별 물체를 유사한 물체들 사이에서 구분하고 조작하는 문제”로 정식화하고, 이를 평가하기 위해 두 가지 시뮬레이션 벤치마크와 실제 로봇 평가 환경을 구축하였다.이는 기존 평가가 주로 물체 범주 수준의 일반화에 머물렀던 한계를 넘어, 실제 인간-로봇 상호작용에 필요한 개별 물체 수준의 개인화를 본격적으로 다룬다는 점에서 의미가 있다.
실험 결과, VAP는 기존 VLA 모델, 언어 설명 기반 프롬프트 방식, 학습 토큰 기반 개인화 방식보다 높은 성공률과 올바른 물체 조작 성능을 보였다. 특히 시뮬레이션과 실제 로봇 환경 모두에서 개인 물체 식별 및 조작 성능을 크게 향상시키면서도, 제어 단계당 약 0.02초의 작은 추적 비용만 추가하여 실시간 제어 가능성을 유지하였다.
또한 본 연구는 정적 이미지에서 물체를 알아보는 능력이 곧 실제 조작 성공으로 이어지지는 않음을 보였다. 학습 토큰 기반 방식은 정적 이미지 인식 단계에서는 개인 물체를 어느 정도 구분할 수 있었지만, 폐루프 조작 과정에서는 주의가 시간에 따라 흔들리거나 유사한 다른 물체로 옮겨가는 한계를 보였다. 반면 VAP는 매 프레임 외부 시각 표시를 통해 물체의 정체성을 다시 고정함으로써, 기존 모델의 일반 조작 능력을 사용자별 물체 조작으로 확장하였다.
[연구결과의 진행 상태 및 향후 계획]
- 본 연구는 기계학습 분야 최고 권위 학술대회 중 하나인 ICML 2026에 게재가 확정되어 발표될 예정이다. 또한 공식 구현 저장소를 통해 코드, 실행 스크립트, 평가 환경 설정 방법이 공개되어 있어 연구 결과를 재현할 수 있다.
[성과와 관련된 실적]
- Lee, S., Mo, S., and Han, W., “Bring My Cup! Personalizing Vision-Language-Action Models with Visual Attentive Prompting,” In Proc., the 43rd International Conference on Machine Learning, ICML, Seoul, South Korea, July 2026.
[성과와 관련된 프로젝트 홈페이지]
https://vap-project.github.io/
[성과와 관련된 이미지]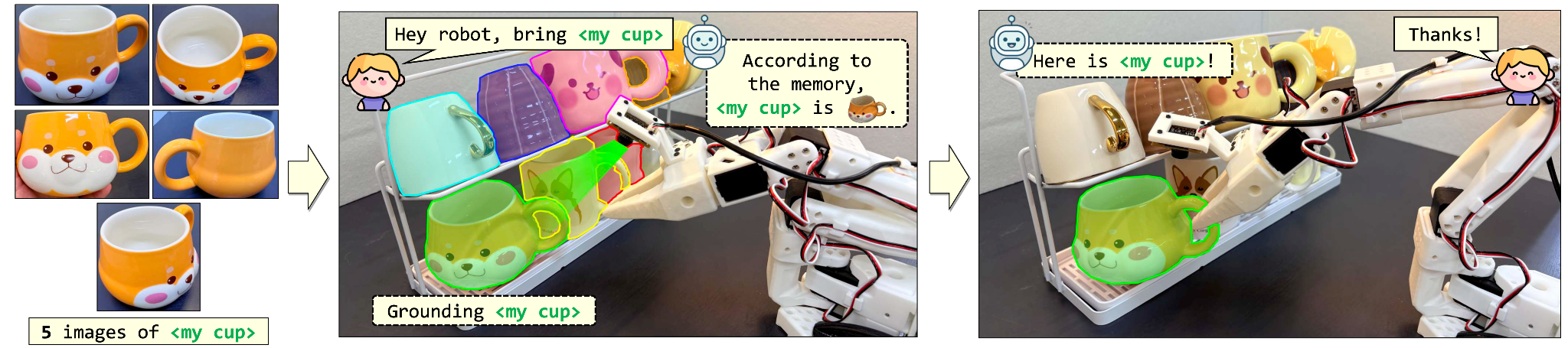 그림 1. 참조 사진으로 사용자의 개인 물체를 찾아 시각적으로 표시하고 조작을 유도하는 VAP의 핵심 아이디어.
그림 1. 참조 사진으로 사용자의 개인 물체를 찾아 시각적으로 표시하고 조작을 유도하는 VAP의 핵심 아이디어.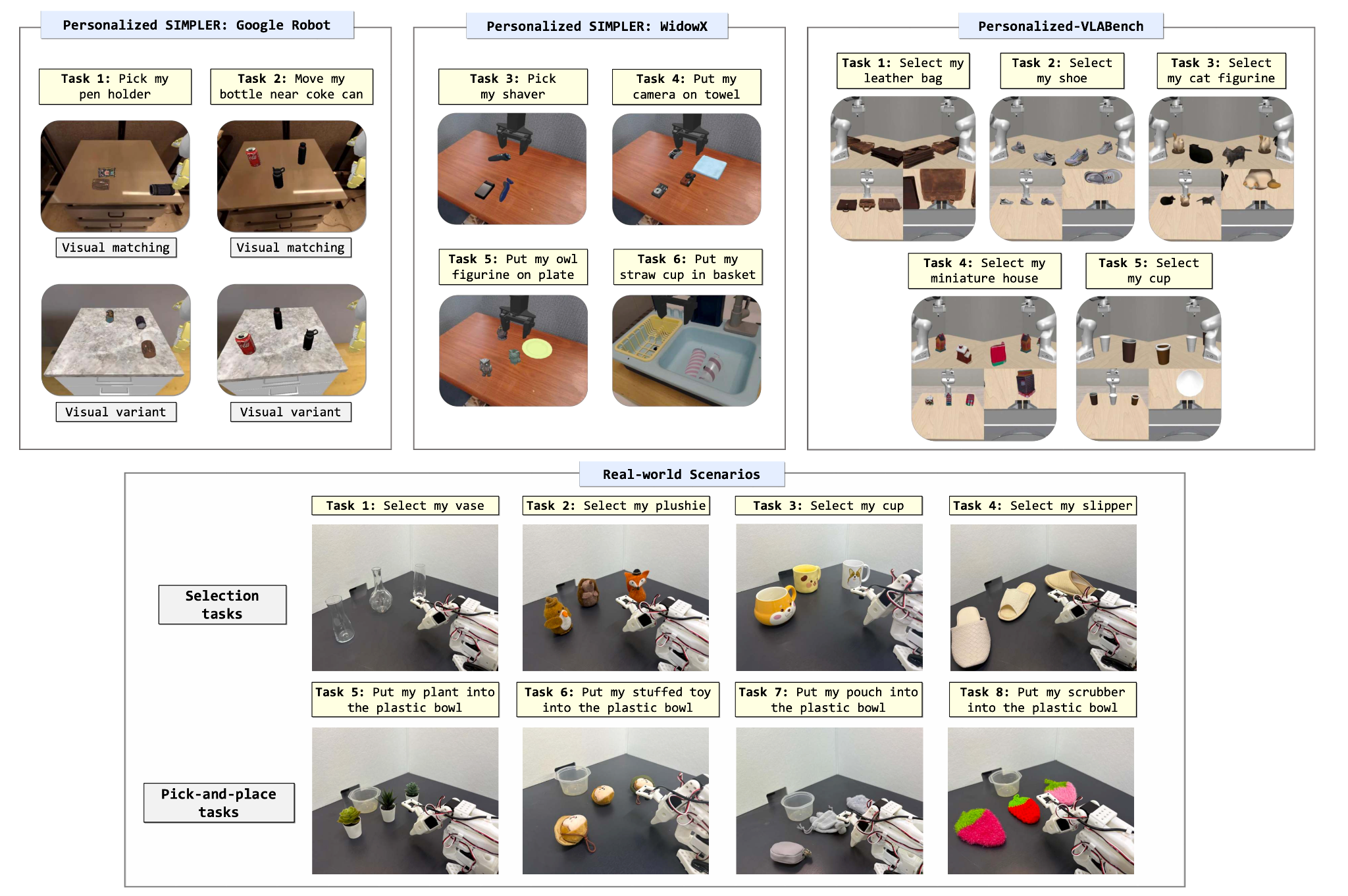 그림 2. 유사 물체들 사이에서 참조 사진만으로 개인 물체를 찾아 조작해야 하는 VAP 평가 벤치마크.
그림 2. 유사 물체들 사이에서 참조 사진만으로 개인 물체를 찾아 조작해야 하는 VAP 평가 벤치마크.
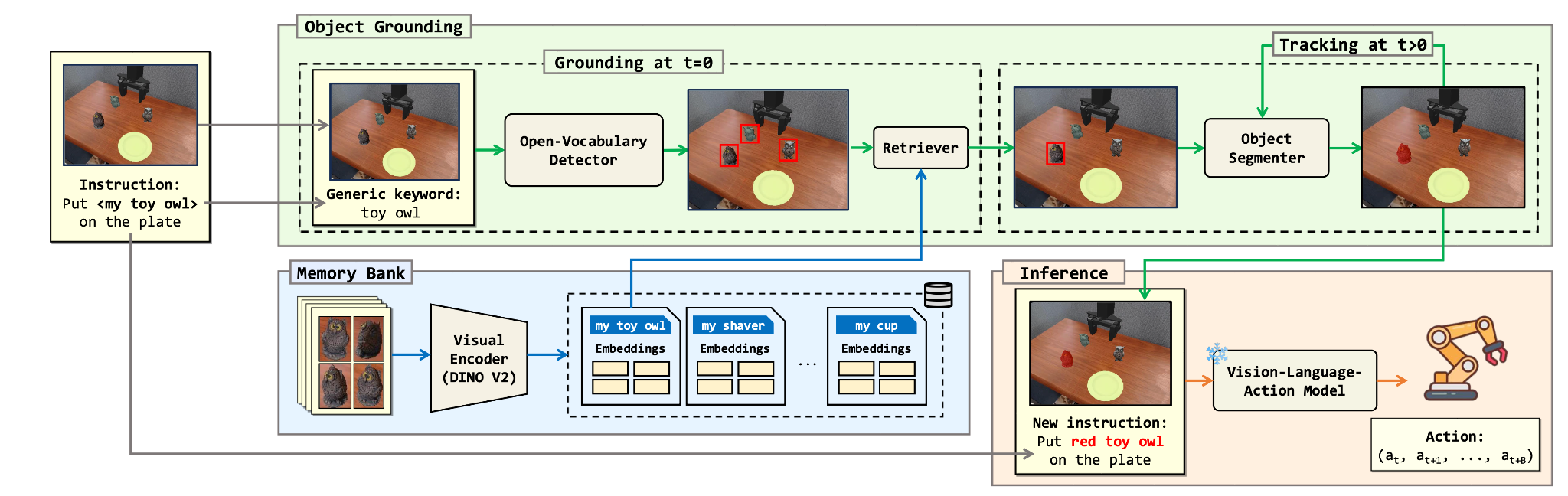
그림 3. 시각 기억, 물체 식별, 마스크 추적, 시각 표시와 명령문 재작성을 결합한 VAP의 전체 처리 흐름.
