최신연구
[한욱신 교수] 머신러닝을 위한 최적 테이블 샘플링 방법 개발
[연구의 필요성]
머신러닝 및 심층 학습(딥러닝) 모델을 잘 학습하기 위해서는 양질의 데이터가 필요한데, 대용량 엔터프라이즈 데이터의 경우 많은 테이블 형태로 분산되어 저장되어 있고 이들은 조인(join) 관계로 연결되어 있다. 이 테이블들을 학습 데이터로 사용하기 위해서는 테이블들에 조인을 수행하여 하나의 거대한 테이블로 만들어야 한다. 문제는 조인된 테이블 크기가 매우 커 저장하기 어렵고 조인 자체가 매우 느릴 수 있다. 따라서, 조인을 직접 수행하지 않고도 조인된 테이블로부터 일부 데이터를 빠르게 샘플(sample)해야 한다. 문제는 이러한 기존 방법들의 경우 미리 확률 분포를 계산한 뒤에 샘플링을 수행하기 때문에, 이 계산량이 입력 데이터에 비례해 임의로 커질 수 있다는 것이다.
[포스텍이 가진 고유의 기술]
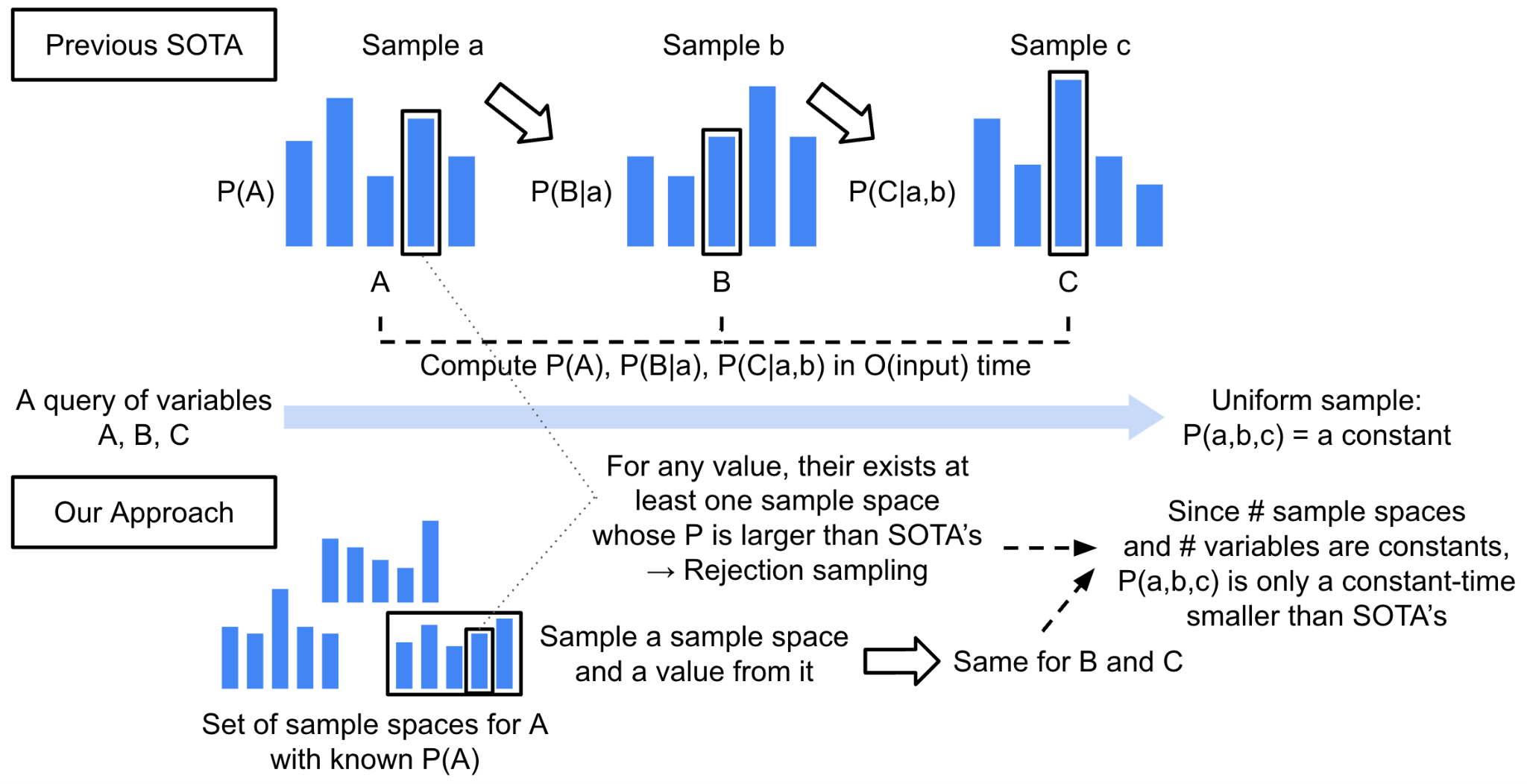
본 기술의 핵심 아이디어는 미리 원하는 확률 분포를 계산한 뒤에 샘플링을 수행하는 것이 아니라, 여러 샘플 공간 중 적어도 하나는 원하는 확률 분포와 비슷한 성질을 가짐을 증명하여, 여러 샘플 공간 중 하나의 샘플 공간을 뽑고, 여기서 확률 분포의 계산 없이 샘플링을 직접 수행하는 것이다. 이러한 메타 샘플링(meta sampling) 기법을 통해, 샘플 공간을 샘플하는 적은 비용을 통해 확률 분포의 계산 비용을 없앨 수 있다. 이를 통해 일반적인 상황에서 이론적으로 최적의 샘플링 기법을 개발하였으며, 더 나아가, 테이블들을 그룹지어 트리 형태로 구조화함으로써 특정 조건 하에서 이론적으로 더 빠른 샘플링이 가능함을 보였다.
[연구의 의미]
제안된 기술을 활용하면 많은 테이블들이 조인 관계로 연결된 데이터에서 빠르게 데이터를 샘플할 수 있어, 머신러닝 및 딥러닝 모델 학습에 효과적이며, 데이터베이스 질의 최적화 및 결과 근사 등 여러 문제에 적용이 가능한 유용한 기술이다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 데이터베이스 이론 분야 최고 학술대회인 ACM PODS 2023에 발표될 예정이며, 42년 학회 역사상 처음으로 한국에서 발표된 논문으로 그 의미가 크다. 이번 연구의 핵심 기술을 기반으로 머신러닝 및 데이터베이스 문제에 응용하는 것이 향후 계획이다.
[성과와 관련된 실적물]
1. Kim, K., Ha, J., Fletcher, G., and Han, W., “Guaranteeing the O(AGM/OUT) Runtime for Uniform Sampling and Size Estimation over Joins,” In Proc., 42nd Symposium on Principles of Database Systems, ACM PODS, Seattle, USA, June 2023. (Corresponding author)
[성과와 관련된 이미지]