최신연구
[한욱신 교수] 조 단위 그래프를 처리하는 분산 그래프 엔진 기술 개발
[연구의 필요성]
그래프는 소셜 그래프의 네트워크 구조, 로드 네트워크, 단백질 상호작용 구조, 웹페이지의 연결구조, 뇌의 신경망 구조 등 현실 세계의 복잡한 데이터를 표현하는 방법으로 널리 사용되고 있다. 최근 들어 그래프 데이터의 크기가 빠르게 증가함에 따라, 수천억 개의 간선으로 구성된 소셜 그래프로부터 수백조 규모의 뇌 신경망에 이르는 초대규모의 그래프 데이터를 효율적이며 안정적으로 처리하는 분산 그래프 엔진 기술의 개발이 중요한 연구 주제로 활발하게 연구되고 있다. 더불어 정적인 그래프 데이터를 다루던 기존 연구들의 한계를 극복하고 소셜 그래프나 뇌 네트워크와 같이 동적으로 구조가 변하는 동적 그래프를 효율적으로 처리하는 연구도 주목을 받고 있다.
[포스텍이 가진 고유의 기술]
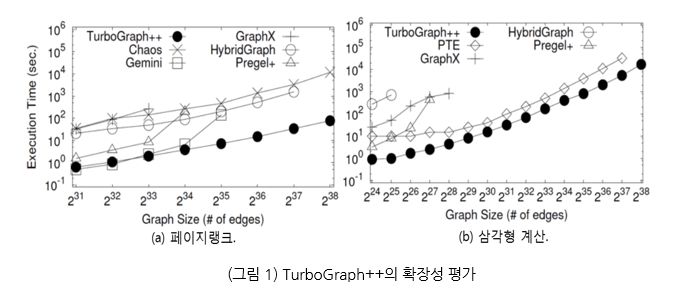
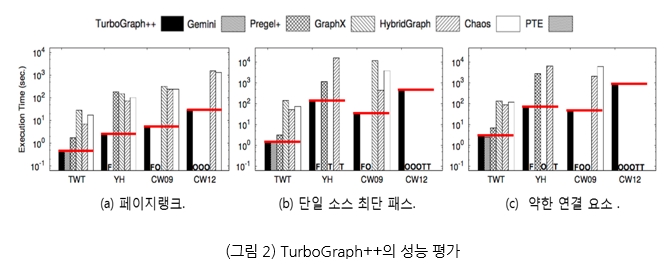
한욱신 교수는 삼성미래기술육성재단의 지원(2014.6~2018.5)을 받아 조 단위 규모의 그래프를 효율적이며 안정적으로 처리하는 분산 그래프 엔진인 TurboGraph++[1]를 개발하고 이 결과를 데이터베이스 분야 최우수 국제 학술대회인 ACM SIGMOD 2018에 논문으로 게재하여, 그래프 처리 및 분석 엔진 분야에서 국내 기술의 위상을 제고하였다. TurboGraph++는 기존의 모든 그래프 처리 엔진들이 극복하지 못한 조 단위 규모의 초대규모 그래프 처리 불가능의 문제를 해결한 획기적인 시스템으로 그 우수성을 인정받아 삼성미래기술육성재단의 우수성과 사례로 후속 과제(2018.9~2021.8)에 선정되었다. TurboGraph++는 새로운 그래프 처리 모델인 중첩 윈도우 스트리밍 모델(Nested Windowed Streaming Model)을 기반으로 제한된 용량의 메모리만을 가지고도 조 단위 규모의 대규모 그래프를 확장성 있고 안정적으로 처리할 수 있는 유일한 시스템이다 (그림 1). 또한, 현대 하드웨어의 병렬 처리 기능을 활용하여 CPU 연산, 디스크 I/O 및 네트워크 I/O를 완전하게 중첩함으로써 기존 연구보다 수백 배까지 빠르게 그래프 처리가 가능하다 (그림 2).
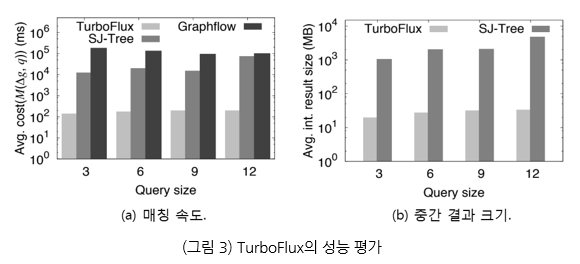
서브 그래프 매칭은 그래프 처리 분야에서는 중요한 연산 중 하나로서, 많이 연구되어 온 바 있다. 그러나 대부분의 기존 연구들은 정적인 그래프를 대상으로 하므로, 소셜 그래프나 뇌 네트워크와 같이 정점 간의 연결 구조가 동적으로 변화하는 환경에 적용하기에는 한계가 있다. 한욱신 교수는 동적 그래프에서 서브 그래프 매칭을 빠르게 수행하는 기술인 TurboFlux[2]를 개발하고 결과를 ACM SIGMOD 2018에 논문으로 게재하였다. 기존의 연구들은 서브 그래프 매칭의 부분 결과를 저장하는 비용이 많이 들거나, 그래프 업데이트 때마다 이미 수행한 매칭 연산을 다시 수행하여 성능이 매우 나쁜 문제가 있다. TurboFlux는 작은 용량의 메모리만으로 부분 결과를 유지하는 데이터-중심(Data-Centric) 그래프와 그래프 업데이트 연산이 발생하였을 때 저비용으로 데이터 중심 그래프를 관리하는 간선 전환(edge transition) 모델을 기반으로, 기존의 연구보다 평균적으로 수만 배까지 빠르게 서브 그래프 매칭을 수행한다 (그림 3).
더불어 한욱신 교수는 데이터 복제 구조를 획기적으로 개선한 하나 비동기 병렬 테이블 복제 기술을 개발하여, 분야 권위 저널인 VLDB 저널에 논문으로 게재[3]하였으며, 클러스터링 알고리즘인 k-메도이드(k-medoids) 알고리즘의 성능을 획기적으로 개선한 병렬 k-메도이드 알고리즘인 PAMAE[4]를 개발하고 그 결과를 데이터 마이닝 분야 최우수 국제학술대회인 KDD 2017에 논문으로 게재하였다. PAMAE를 TurboGraph++에 적용하면 조 단위 그래프에 대한 클러스터링도 가능하게 된다.
[연구의 의미]
한욱신 교수는 빅 그래프 데이터 처리 분야에서 획기적인 아이디어와 우수한 결과물을 통해 분야의 학술적 발전에 크게 이바지하고 있다. 한 교수는 데이터베이스 분야의 최우수 국제학술대회인 ACM SIGMOD에 국내 주도 연구로는 가장 많은 13편의 논문을 게재하였으며, ACM SIGMOD 뿐만 아니라, 동 분야 최우수 국제학술대회인 VLDB(10편), 데이터 마이닝 분야 최우수 국제학술대회인 KDD(3편) 등에도 꾸준히 논문을 게재하여 분야에서 국내 기술의 위상을 높이고 있다. 이처럼 결과물의 학술 가치를 세계적으로 인정받았을 뿐만 아니라, 우수한 성능과 경제성으로 인한 높은 산업적 임펙트 때문에 에스에이피, 오라클, 삼성 등의 IT분야 최우수 기업들의 지속적인 지원을 받아 연구를 진행하고 있다.
TurboGraph++는 이제까지 어떤 그래프 처리 엔진도 해결할 수 없었던, 조 단위 규모의 초대용량 그래프 처리를 소규모의 머신만으로 구성된 클러스터를 이용하여 효율적이며 안정적으로 처리할 수 있어, 웹 그래프 분석, 뇌 질환 분석과 같이 초대규모 그래프를 다뤄야 하는 검색엔진, 의료 등의 산업을 포함하여 그래프 데이터를 다루는 산업 전반의 발전에 이바지할 수 있을 것이다. TurboFlux는 동적 그래프 기반의 그래프 매칭을 해야 하는 소셜 데이터 분석, 침입 탐지, 이상 금융 거래 탐지 등의 고부가가치 산업에 활용될 수 있다. 비동기 병렬 테이블 복제는 상용 DBMS인 하나의 핵심 모듈로 활용 가능하며, 병렬 k-메도이드 기술은 데이터 마이닝 분야의 기반 기술인 클러스터링 기술로서 IT 산업 전반에서 활용이 가능한 유용한 기술이다.
[연구결과의 진행 상태 및 향후 계획]
상기 언급한 바와 같이 한욱신 교수는 대용량 그래프 데이터 처리 분야에서 학술 및 산업적으로 임펙트가 큰 연구를 수행해오고 있으며, 이를 통해 데이터베이스 및 데이터마이닝 분야에서 국내 기술의 위상을 높이는 데 크게 이바지하고 있다.
최근에는 동적 그래프 처리 기술을 대용량 분산 그래프 처리 엔진에 접목한 점진적 및 시간 지원 그래프 분석을 지원하는 조 단위 규모의 빅 그래프 분석 엔진을 개발하고 있다. 또한, 딥러닝 기술에 기반을 두어 자연어 인터페이스를 제공하는 지능형 DBMS를 개발하고 있다.
[성과와 관련된 실적물]
1. Ko, S., and Han, W., “TurboGraph++: A Scalable and Fast Graph Analytics System,” In 44th Int’l Conf. on Management of Data, ACM SIGMOD, Houston, USA, June 2018.(Corresponding author)
2. Kim, K., Seo, I., Han, W., Lee, J., Hong, S., Chafi, H., Shin, H., and Jeong, G., “TurboFlux: A Fast Continuous Subgraph Matching System for Streaming Graph Data,” In 44th Int’l Conf. on Management of Data, ACM SIGMOD, Houston, USA, June 2018.(Corresponding author)
3. Lee, J., Han, W., Na, H., Park, C., Kim, K., Kim, D., Lee, J., Cha, S., and Moon, S. “Parallel Replication across Formats for Scaling Out Mixed OLTP/OLAP Workloads in Main-Memory Databases,” The VLDB Journal, pp.1-24, April 2018.
4. Song, H., Lee, J., and Han, W., “PAMAE: Parallel k-Medoids Clustering with High Accuracy and Efficiency,” In 23rd ACM KDD Conference on Knowledge Discovery and Data Mining, Halifax, Nova Scotia, Canada, Aug. 2017.
[성과와 관련된 이미지]