최신연구
[한욱신 교수] 머신러닝에 기초한 효과적이고 효율적인 JSON 스키마 추론 방법
[연구의 필요성]
웹 API 데이터 교환, 빅데이터 분석 등 현대의 데이터 중심 응용 소프트웨어에서는 JSON 데이터 형식의 사용이 점차 증가하고 있다. JSON 데이터는 스키마 없이 사용 가능한 유연성 덕분에 빠르게 확산되어 사용되고 있지만, 이로 인해 대규모 JSON 데이터의 효율적인 처리가 어려워지고 질의 성능이 저하되는 문제가 발생한다. 따라서, 스키마가 명시되어 있지 않은 JSON 문서들에서 JSON 스키마를 자동으로 추론하는 기술이 절실히 요구된다.
[포스텍이 가진 고유의 기술]
본 연구에서 ReCG는 JSON 스키마 추론 문제를 탐색 문제로 정의하고, 머신러닝 기법들을 사용하여 다양한 후보 스키마를 체계적으로 탐색하여 최적의 스키마를 도출한다 (그림 1). 또한, 트리 구조의 JSON 스키마를 위에서부터 아래로 생성하는 기존의 하향식 스키마 생성법의 한계를 지적하며 스키마를 아래에서부터 위로 생성하는 상향식 스키마 생성법을 소개한다. 이를 통해 이전 단계에서 생성된 스키마 정보를 이용하여 보다 정확한 스키마의 후보를 생성할 수 있다. 이러한 접근 방식은 기존 JSON 스키마 추론법의 한계를 극복하고, 더 정확한 JSON 스키마의 추론을 가능하게 한다. ReCG는 기존의 최고 성능 스키마 추론법과 비교하여 46%의 정확도 향상을 보인다 (그림 2).
[연구의 의미]
ReCG를 활용하면 JSON 문서의 스키마를 자동으로 추론하여 데이터 검증, 질의 최적화, 데이터 이주 등 다양한 작업을 효율적으로 수행할 수 있다. 이 기술은 특히 스키마가 명확하지 않은 대규모 JSON 데이터를 다루는 웹 API 서비스, 빅데이터 분석 등 다양한 분야에서 활용 가능한 유용한 기술이다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 데이터베이스 분야 최고 학술대회인 VLDB 2024에 발표될 예정이다. 향후 계획으로는 ReCG에서 사용되는 매개 변수를 데이터의 특성에 맞춰 자동적으로 결정하는 연구와, 하향식과 상향식 스키마 생성법을 결합한 동적 스키마 생성법에 대해 연구하고자 한다.
[성과와 관련된 실적]
Yun, J., Tak, B., and Han, W., “ReCG: Bottom-Up JSON Schema Discovery Using a Repetitive Cluster-and-Generalize Framework”, In 50th Int’l Conf. on Very Large Data Bases (VLDB) / Proc. the VLDB Endowment (PVLDB), Aug. 2024 (Corresponding Author)
[성과와 관련된 이미지]
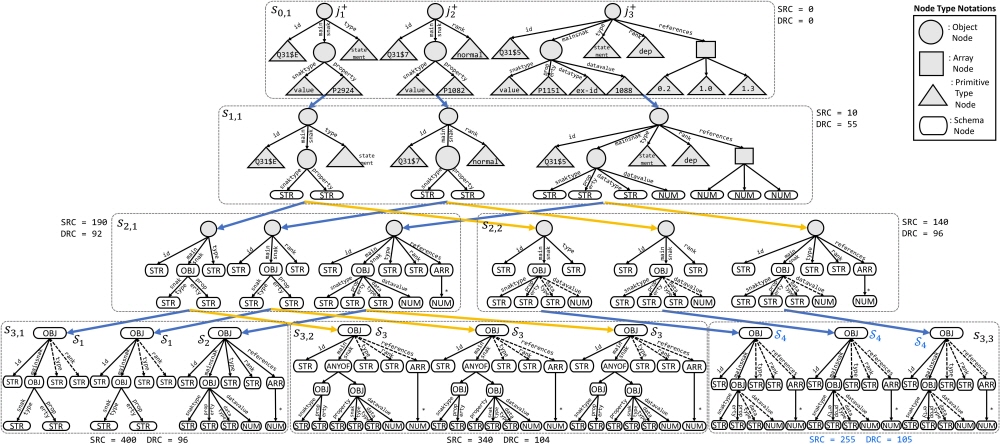
그림 1. ReCG가 JSON 문서로부터 JSON 스키마를 찾는 탐색 과정에 대한 시각화. 상태(네모 모양)가 전이됨에 따라 스키마 노드들이 아래에서부터 위쪽으로 생성되는 상향식 스키마 생성법을 채택한다.
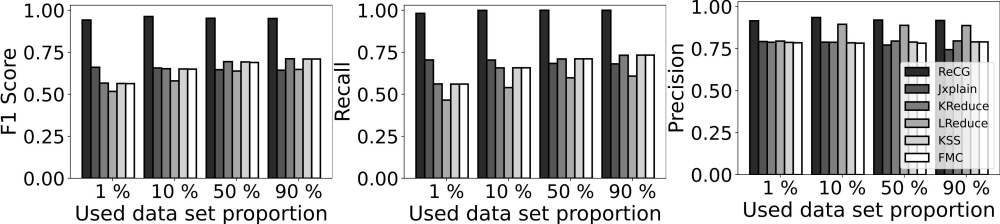
그림 2. ReCG의 성능 평가. ReCG는 기존에 최고 성능을 보이던 알고리즘인 Jxplain과 비교하여 46%의 F1 점수의 향상을 보인다.