최신연구
[한욱신 교수] 데이터베이스 질의 최적화를 위한 머신러닝 기반 질의 결과 개수 예측 방법
[연구의 필요성]
데이터베이스 질의 최적화는 사용자가 요청한 데이터베이스 질의를 사용자에 맡기지 않고 데이터베이스가 알아서 최적화를 진행해 수행하는 것으로, 질의를 수행할 수 있는 수많은 플랜(plan) 중 가장 빠를 것으로 예상되는 플랜을 선택한다. 이를 위해 각 플랜의 예상 시간을 미리 예측해야 하는데, 가장 빠른 것과 느린 것의 차이가 만 배 이상 나오기도 하므로, 매우 느린 플랜을 선택하지 않기 위해 정확한 예측이 필수적이다. 예상 시간을 예측할 때 가장 중요한 요인 중 하나는 질의 수행 결과의 크기 혹은 개수(cardinality)이므로, 이를 정확하게 예측하는 것이 매우 중요하며, 더 나아가 질의의 최종 결과 개수 뿐만 아니라 플랜이 생성하는 서브질의(subquery)들의 결과 개수들을 전부 예측해야 한다. 최근 머신러닝의 발전으로 데이터 분포를 학습해 예측에 사용하는 등, 예측의 정확도는 크게 향상되어 보다 빠른 플랜을 선택할 수 있게 되었으나, 예측 속도는 이전보다 크게 느려져, 결국 최적화와 수행에 걸리는 전체 시간(end-to-end execution time)은 크게 나아지지 않았다. 가장 최신의 연구 또한, 예측 속도를 높이기 위해 동적 프로그래밍(dynamicprogramming) 기법을 사용했는데, 예를 들어 테이블 A, B를 포함하는 서브질의 q1의 예측 결과 개수를, 테이블 A, B, C를 포함하는 서브질의 q2의 결과 개수를 예측할 때 재사용한다. 이때 문제는, q1의 테이블들의 데이터 분포와 q1에 없던 테이블 C의 데이터 분포가 독립적(independent)임을, 즉 서로 연관이 없음을 가정하는데, 이 비현실적인 가정 때문에 예측 정확도가 크게 낮아지기도 했다. 따라서, 예측 속도와 정확도를 둘 다 높일 수 있는 방법이 필요하였다.
[포스텍이 가진 고유의 기술]
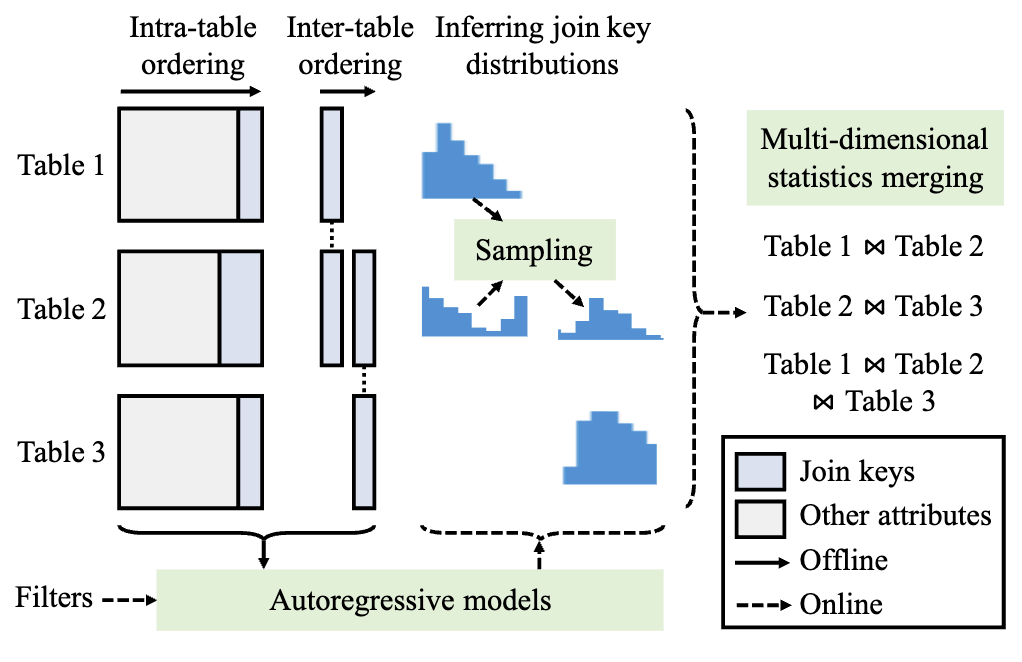
본 기술은 머신러닝과 동적 프로그래밍을 사용하면서도, 언급한 데이터 분포의 독립성을 가정하지 않고 정확하게 예측하는 방법을 제안한다. 먼저 머신러닝 모델 중 비지도학습 기반 자기회귀모델(autoregressive model)을 사용하여 질의에 포함된 각 테이블의 분포를 예측한다. 그 뒤 샘플링(sampling)에 기반하여 이 분포들을 독립성 가정 없이 합쳐, 여러 테이블을 포함하는 서브질의의 결과 개수를 정확하게 예측한다. 마지막으로 다차원 분포 합침(multi-dimensional statistics merging)은 샘플링과 동적 프로그래밍 기법을 융합하여 수천에서 수만 개의 서브질의에 대해 효율적으로 예측한다.
[연구의 의미]
본 연구는 정확한 결과 개수 예측으로 데이터베이스 질의 최적화에 적용시 최적(optimal)에 가까운 플랜들을 선택하였고, 빠른 예측 속도로 최적화 시간을 효율적으로 유지하여, 이전 최신 연구보다 최대 300배 가까이 질의 수행 시간을 단축시켰다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 데이터베이스 시스템 분야 최고 학술대회인 ACM SIGMOD 2024에 발표될 예정이다. 향후 더 크고 복잡한 질의에 대해서도 높은 예측 정확도와 빠른 예측 속도를 지원하는 방법을 개발하고자 한다.
[성과와 관련된 실적]
Kim, K. Lee, S., Kim, I., Han, W.-S. “ASM: Harmonizing Autoregressive Model, Sampling, and Multi-dimensional Statistics Merging for Cardinality Estimation.” Proceedings of the ACM on Management of Data 2.1 (2024), pp. 45:1–45:27. (Corresponding author)
[성과와 관련된 이미지]