최신연구
[한욱신 교수] 다수의 작은 질의를 분산환경에서 확장성 있게 처리하는 기술의 개발
[연구의 필요성]
최근 데이터 분석 응용들은 Spark와 같은 빅데이터 처리 플랫폼에 크게 의존하고 있다. 기존의 빅데이터 분석 플랫폼은 질의 당 대규모 데이타가 액세스되는 경우를 효율적으로 처리할 수 있도록 설계되고 최적화되었다. 그러나 하나의 질의에서 액세스하는 데이타는 크지 않지만 이런 질의들의 숫자가 매우 많은 경우에는 기존 빅데이타 분석 플랫폼을 그대로 사용하게 되면 성능상의 문제점이 발생하게 된다.
[포스텍이 가진 고유의 기술]
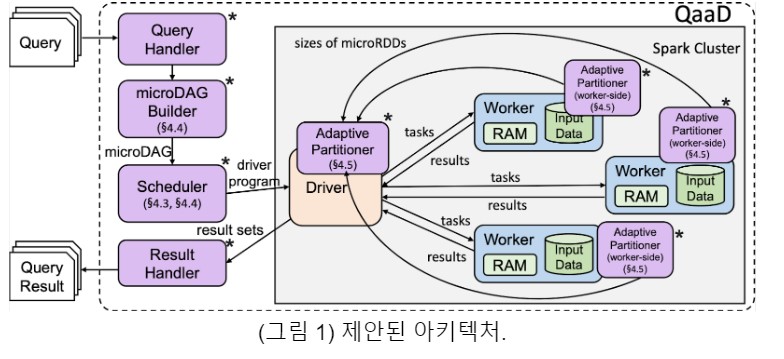
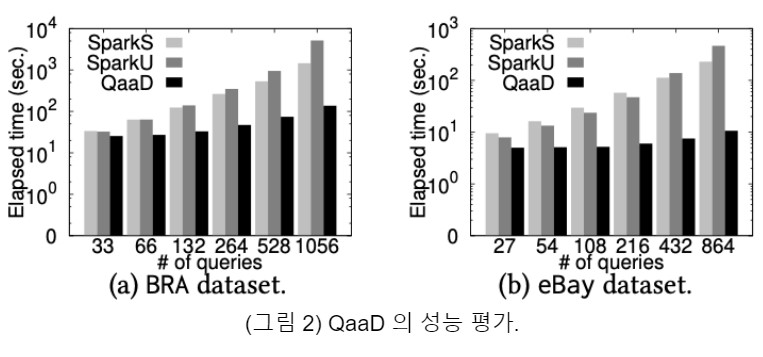
본 기술의 핵심 아이디어는 질의를 데이타의 일부로 임베드하고, 동일한 서브질의들을 공유해서 한번에 처리하는 것이다. 해당 기술은 Spark뿐만 아니라 대규모 데이타 처리 시스템에 적용될 수 있는 확장성을 가지고 있다 (그림 1). 이렇게 함으로써 워크로드 처리 시 설정 대비 계산 시간 비율 (setup-to-compute time ratio)이 크게 개선되며, 질의 처리 시 필요한 머신 간 데이터 전송을 최소화하기 위하여 가능한 질의가 접근하는 데이터를 클러스터 내 동일 머신에 배치함으로써 대량의 작은 질의 워크로드를 10.6배에서 36.6배까지 빠르게 처리한다 (그림 2).
[연구의 의미]
제안된 기술을 활용하면 대량의 작은 질의를 효율적으로 처리할 수 있어, 이커머스, 미디어, 클라우드 컴퓨팅을 포함하여 작은 질의가 대량으로 발생하는 산업 전반에서 활용이 가능한 유용한 기술이다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 데이타베이스 분야 최고 학술대회인 ACM SIGMOD 2023에 발표될 예정이며, 이번 연구의 핵심 기술을 기반으로 단일 머신 및 분산 환경에서 초대규모 그래프 데이터의 처리하는 연구에 접목하고자 하는 것이 향후 계획이다.
[성과와 관련된 실적물]
1. Park, Y., Tak, B., and Han, W., “QaaD (Query-as-a-Data): Scalable Execution of Massive Number of Small Queries in Spark,” In 49th Int’l Conf. on Management of Data, ACM SIGMOD, Seattle, USA, June 2023. (Corresponding author)
[성과와 관련된 이미지]