최신연구
[이근배/옥정슬 교수] An Investigation Into Explainable Audio Hate Speech Detection
[연구의 필요성]
오디오 기반의 SNS 등의 플랫폼(i.e. YouTube, TikTok) 등이 증가 함에 따라 증오표현이 포함된 오디오 content이 굉장히 증가했습니다. 따라서 이러한 유해한 content를 필터링 해야 하는 필요성이 생겼습니다. 이 때, 전체 오디오가 유해한지 아닌지 판단하는 것을 넘어서, 해당 오디오 안에서 구체적으로 어떤 부분이 증오표현인지 판단하는, 설명가능한, 방법론이 중요해 졌습니다.
그러나, 현재까지 오디오에서 설명가능한 증오표현 탐지 연구는 한 번도 이루어진 적이 없었기 때문에 우리는 이 문제를 처음으로 해결해보고자 했습니다.
[포스텍이 가진 고유의 기술]
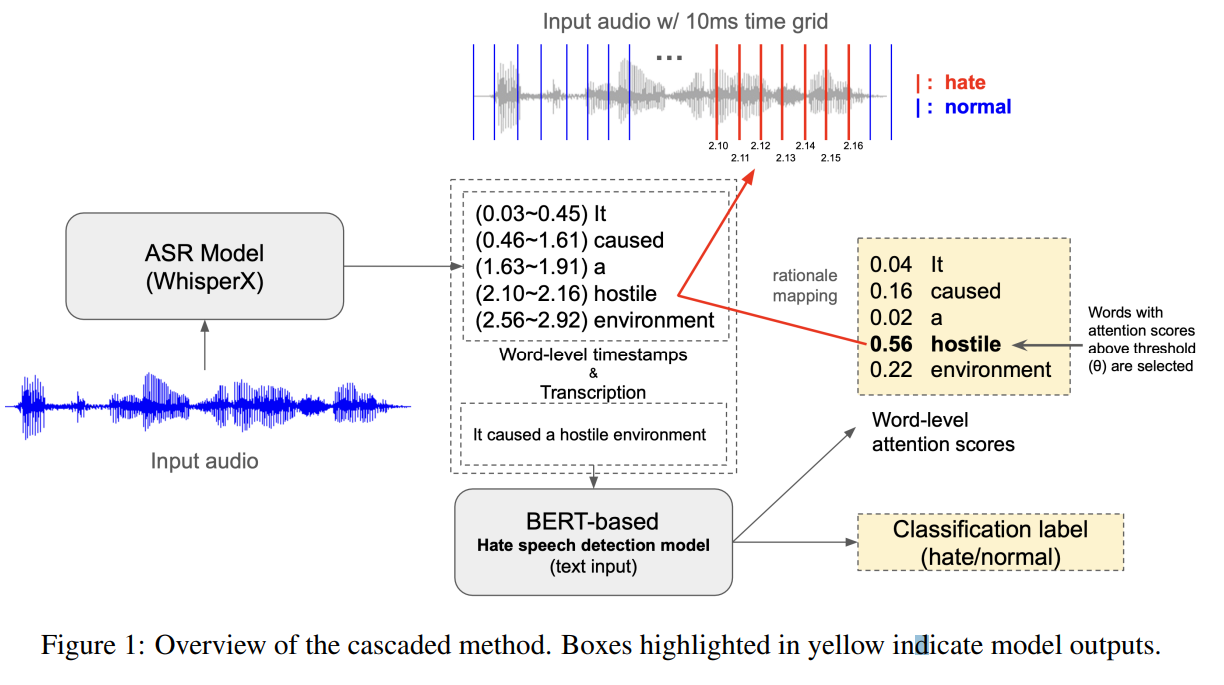
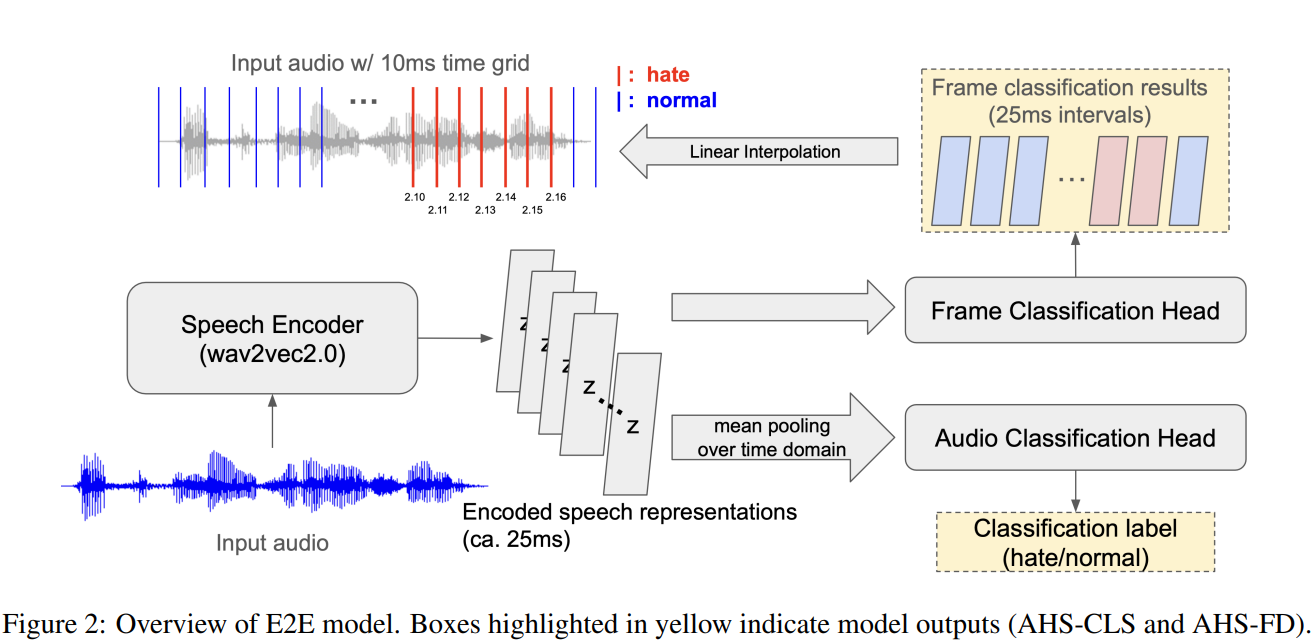
이 테스크를 수행하기 위해 크게 2가지를 진행했습니다. 첫째로 설명가능한 증오표현 오디오 데이터셋을 최초로 제작했습니다. TTS(Text-To-Speech) 또는 실제 사람의 육성을 기반으로 한 오디오 데이터셋을 구축하고, 해당 오디오에서 증오표현이 어떤 시간 구간에서 발생하는지 annotation을 진행했습니다. 두번째로 설명가능한 증오표현 탐지 모델을 제안했습니다. 이 모델은 오디오를 input으로 받고 전체 오디오가 증오표현이 포함되었다고 판단되었을 때, 어떤 시간구간이 증오표현이 포함되었는지 알려주는 모델입니다. 모델은 오디오를 End-to-End(E2E)로 사용하는 방식, 오디오를 텍스트로 바꿔서 사용하는 Cascading 방식으로 2가지 종류가 있습니다.
[연구의 의미]
본 연구는 크게 2가지 의미가 있습니다. 우선 이 연구는 최초로 설명가능한 오디오 탐지 분야를 개척한 연구입니다. 설명가능한 오디오 데이터셋이란 무엇이고, 어떤 모델을 사용할 수 있고, 또한 어떤 평가 지표로 오디오의 설명가능성을 측정할 수 있는지 제안했습니다. 두 번째로는 설명가능한 오디오 증오 표현 탐지에는 오디오를 직접적으로 사용하는 E2E가 Cascading 방식보다 효과적이라는 사실을 알아냈고, 그 이유를 분석하기 위한 실험도 진행했습니다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 SIGDIAL 2024에서 포스터 발표되었고, 오디오를 넘어선 다양한 modality에서 설명가능한 증오표현 탐지를 진행할 계획입니다.
[성과와 관련된 실적]
Jinmyeong An, Wonjun Lee, Yejin Jeon, Jungseul Ok, Yunsu Kim, and Gary Geunbae Lee. 2024. An Investigation into Explainable Audio Hate Speech Detection. In Proceedings of the 25th Annual Meeting of the Special Interest Group on Discourse and Dialogue(SIGIDIAL), pages 533–543, Kyoto, Japan.
[성과와 관련된 이미지]