최신연구
[이근배 교수] Prompt-Guided Selective Masking Loss for Context-Aware Emotive Text-to-Speech
[연구의 필요성]
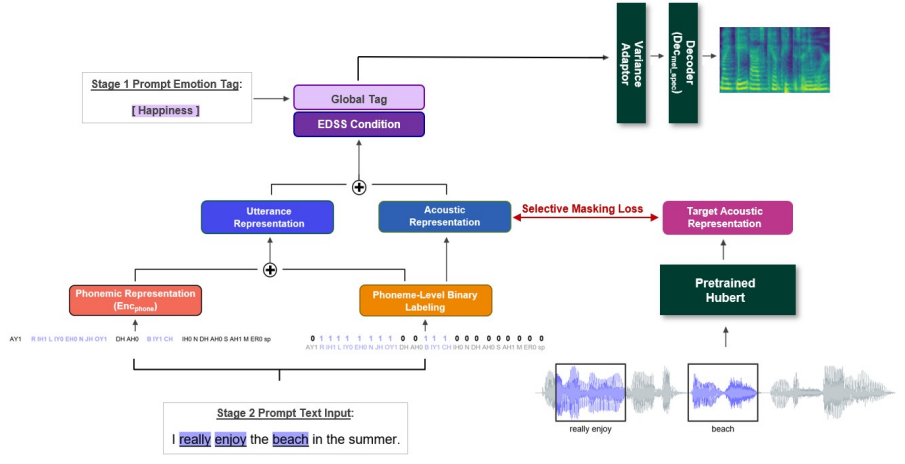
기존 연구들은 대화 문맥을 활용하여 감성적 음성을 합성하는 데 주력해왔으나, 이러한 접근 방식은 실제 인간 대화에서 특정 단어가 감정적으로 강조되는 현상을 효과적으로 반영하지 못하는 한계를 지닌다. 즉, 기존 방법론은 발화 전체의 스타일을 전반적인 조건으로 활용하는 데 집중한 나머지, 감정 전달에 있어 중요한 국소적 음향 단서의 역할을 간과하고 있다. 또한, 대부분의 기존 연구에서는 감정 라벨 또는 참조 음성을 사용자가 수동으로 지정해야 하기 때문에 구조적 제약이 존재한다. 본 연구는 이러한 한계를 극복하기 위해, 대형 언어 모델(LLM)을 활용하여 대화 문맥으로부터 감정 태그를 자동으로 추출하고, 목표 발화 내에서 감성적으로 중요한 핵심 단어를 식별함으로써, 사용자 개입 없이 감성적 음성을 생성할 수 있는 자동화된 파이프라인을 제안한다.
[포스텍이 가진 고유의 기술]
본 연구는 대화 문맥을 고려한 감성 음성 합성(EDSS)에서 전반적인 감정 태그와 국소적인 감성 단서를 동시에 활용하는 새로운 접근 방식을 제안한다. 이를 위해, (1) LLM을 활용하여 대화 문맥 기반 감정 태그를 자동 생성하고, (2) 감정적으로 중요한 키워드를 식별하며, (3) 선택적 오디오 마스킹 로스를 통해 감성적 특징을 보다 정교하게 학습하는 방식을 도입하였다. 또, 기존의 감성 음성 합성 모델이 특정 감정 라벨이나 참조 음성을 필요로 하는 반면, 본 연구는 사용자 개입 없이도 감성적이며 자연스러운 음성을 생성할 수 있는 모델을 개발했다. 실험 결과, 제안된 모델은 기존의 접근법보다 감정 표현력과 발화 자연스러움 측면에서 높은 성능을 보였다.
[연구의 의미]
본 연구는 감성 음성 합성에서 문맥 정보와 국소적인 감성 단서를 결합한 최초의 연구로서, 기존 방법론의 한계를 극복하고 보다 자연스럽고 감성적인 음성을 생성하는 새로운 방법론을 제시한다. 이러한 방법론은 감성 대화 음성 합성뿐만 아니라, 음성 인터페이스, 인간-컴퓨터 상호작용 등 다양한 분야에서 활용될 수 있을 것으로 기대된다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 NAACL 2025에서 발표될 예정이며 향후 멀티모달 시나리오로 확장할 계획이다.
[성과와 관련된 실적]
Yejin Jeon, Youngjae Kim, Jihyun Lee, Gary Geunbae Lee, NAACL 2025 (accepted)
[성과와 관련된 이미지]