최신연구
[이근배 교수] PicPersona-TOD: A Dataset for Personalizing Utterance Style in Task-Oriented Dialogue with Image Persona
[연구의 필요성]
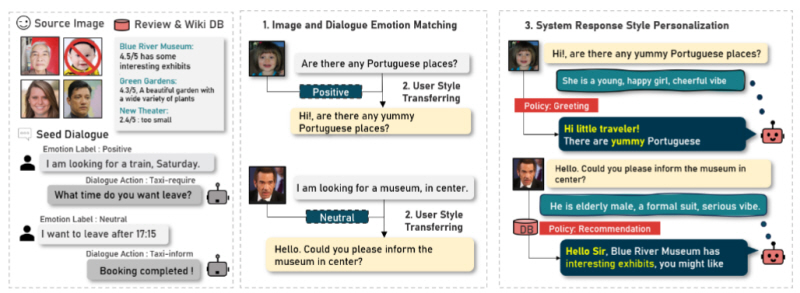
Task-Oriented Dialogue (TOD) 시스템은 사용자의 요청을 이해하고 적절한 정보를 제공하는 AI 기반 대화 시스템이다. 기존 TOD 시스템의 발화 스타일은 정보 전달의 정확성에 집중해 왔으나, 정보 전달만을 목적으로 하였기 때문에, 발화 스타일이 획일적이며 사용자와의 감성적 연결이 부족하다는 한계를 가진다. 특히, 기존의 텍스트 기반 TOD 모델들은 대화를 하고있는 개개인의 세부적인 특성을 실시간으로 반영하지 못해 자연스러운 맞춤형 응답을 제공하는 데 어려움이 있었다. 이를 해결하기 위해, 사용자 이미지를 활용한 새로운 방식의 페르소나 기반 TOD 시스템을 제안한다.
[포스텍이 가진 고유의 기술]
본 연구에서는 vision language model (VLM) 을 활용하여 기존 TOD 시스템을 뛰어넘는 개인화된 대화 모델을 개발 하였다. 사용자 이미지를 통해 연령, 감정, 스타일 등의 비언어적 정보를 추출하는 과정과, 이를 LLM과 결합하여 대화의 자연스러움과 개인화를 강화하엿다. 또한 생성된 데이터셋을 의미와 정확도에 맞춘 필터링을 통해 품질을 높였다. 여기에 Google Maps 및 Wikipedia 등의 외부 지식을 연동하여, 단순한 개인화뿐만 아니라 정보의 신뢰성과 정확성을 동시에 확보할 수 있도록 설계하였다. 이를 통해, 보다 정교한 개인 맞춤형 응답을 제공하는 TOD 시스템을 구현하였다.
[연구의 의미]
사용자 이미지를 활용하여 TOD 시스템의 발화 스타일을 개인화함으로써, 기존 모델의 획일적인 응답 방식과 감성적 연결 부족 문제를 해결하였고, 이를 통해 사용자 맞춤형 대화 경험을 제공하는 새로운 접근법을 제시한다.
[연구결과의 진행 상태 및 향후 계획]
실험 결과, 기존 TOD 시스템 대비 개인화된 응답의 자연스러움과 사용자 만족도가 향상됨을 확인하였다. 추후에는 사용자 피드백을 반영한강화학습을 통해 해당 데이터를 사용하는 모델들의 의 성능을 지속적으로 개선 할 예정이다.
[성과와 관련된 실적]
NAACL 2025 학회 Accept(Jihyun Lee, Yejin Jeon, Seungyeon Seo, Gary Geunbae Lee)
[성과와 관련된 이미지]