최신연구
[이근배 교수] Multi-Level Attention Aggregation for Language-Agnostic Speaker Replication
[연구의 필요성]
기본 음성합성 모델들이 생성하는 음성의 품질이 매우 자연스러워져서, 원하는 사람의 목소리로 음성을 합성하는 다중 화자 TTS 연구가 증가하고 있습니다. 그러나, 기존의 다중 화자 TTS는 특정 언어 내에서만 음성 합성이 가능하기 때문에, 학습 데이터와 다른 언어로 말하는 화자의 목소리를 따라하지 못하는 한계가 있습니다. 따라서, 본 연구에서는 이러한 unseen 언어로 말하는 화자에게도 해당 화자의 목소리로 음성 합성이 가능하도록 하는 방법을 탐색하였습니다.
[포스텍이 가진 고유의 기술]
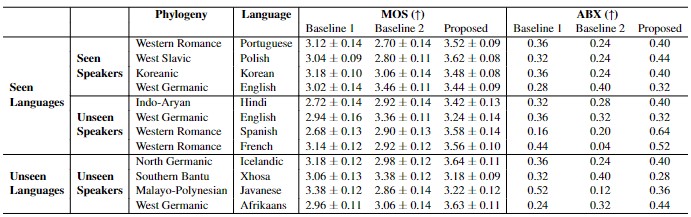
화자의 목소리는 pitch와 timbre 같은 다양한 특징으로 구성되어 있습니다. 이에 따라 기존의 다중 화자 TTS 연구는 이러한 정보를 학습하거나 사전 훈련된 화자 확인 모델을 사용하여 input reference audio에서 화자의 목소리 정보를 직접 추출하는 방법을 채택했습니다. 본 논문은 이러한 모든 방법을 사용하면서도, 다양한 정보를 어떻게 융합해야 언어와 무관하게 화자의 음성을 복제할 수 있는지를 탐구했습니다. 구체적으로는 사전 훈련된 화자 확인 모델을 통해 추출된 reference audio representation을 yin algorithm으로 추출한 pitch관련 representation과 cross attention을 진행하였습니다. 이후, 화자의 전역 timbre 정보를 컨볼루션 블록을 통해 추출하고 이를 이전 aggregation 단계의 아웃풋과 다시 cross attention을 통해 결합합니다. Generalizability를 향상시키기 위해 representation splitting을 진행하였고, 최종적으로 생성된 화자 표현을 기준 TTS 프레임워크에 condition으로 적용했습니다.
[연구의 의미]
본 연구에서는 말하는 언어와 관계없이 화자의 목소리를 추출할 수 있는 새로운 task를 제안하였으며이를 위해 다양한 화자의 목소리 정보를 추출하고 융합하는 최적의 절차를 탐색하였습니다. 실험 결과, 정보 융합을 위한 2단계 절차를 거칠 때 언어와 상관없이 화자의 목소리를 대체적으로 잘 모방할 수 있는 것을 확인할 수 있었습니다.
[연구결과의 진행 상태 및 향후 계획]
처음으로 제시한 테스크인만큼, 성능을 더 높일 수 있는 방법을 탐색할 계획입니다.
[성과와 관련된 실적]
Yejin Jeon, Gary Geunbae Lee, EACL 2024 Accepted
[성과와 관련된 이미지]