최신연구
[이근배 교수] Explainable Multi-hop Question Generation: An End-to-End Approach without Intermediate Question Labeling
[연구의 필요성]
최근 대화형 인공지능 챗봇에 대한 수요가 증가함에 따라 사용자의 복잡한 질문에 응답할 수 있는 기술의 중요성이 커지고 있다. Multi-hop 질문이란 여러 문서에 대한 복합적인 추론을 통해 응답을 찾을 수 있는 복잡한 질문을 뜻한다. 이러한 Multi-hop 질문을 사람이 직접 생성하는 것은 많은 시간과 비용을 요구하기 때문에 본 연구에서는 주어진 문서와 응답을 기반으로 Multi-hop 질문들을 자동으로 생성할 수 있는 방법론을 제안한다.
[포스텍이 가진 고유의 기술]
이전 관련 연구들에서는 입력 문서들과 응답의 인코딩 값을 기반으로 질문을 디코딩하는 end-to-end 접근법을 사용했다. 이러한 접근법은 세 개 이상의 문서를 참조하는 3-hop 이상의 복잡한 질문을 논리적으로 생성하는데 한계가 있다. 본 연구에서는 기존 방법론의 한계를 보완하는 End-to-End Question Rewriting (E2EQR) 모델을 제안한다. E2EQR은 1-hop 질문을 생성한 다음 이를 순차적으로 재작성하여 복잡성을 증가시킨다. E2EQR은 encoder-decoder 구조의 Transformer를 기반으로 하는 순환 신경망 구조를 가진다. 각 단계에서 모델은 입력 문서를 기반으로 이전 단계에서 생성된 질문을 재작성한다. 생성된 질문을 다음 단계에서 모델에 직접적으로 입력하는 대신, 이전 단계에서의 디코더 은닉 상태를 다음 단계 디코딩 과정에서 활용한다. 이를 통해 중간 단계 질문들에 대한 정답 없이 최종 생성 질문에 대한 정답만을 이용해 전체 모델을 훈련시키는 end-to-end 훈련이 가능해진다. E2EQR은 간단한 1-hop 질문 데이터부터 순차적으로 복잡한 질문 예제들을 학습하는 curriculum learning 방식을 통해 훈련되었으며, 초반에 학습한 쉬운 예제에 대한 catastrophic forgetting을 방지하면서도 서로 다른 복잡도의 예제들에 대해 균일한 성능 보이도록 하는 Adaptive Curriculum Learning 방식을 함께 제안한다.
[연구의 의미]
본 연구에서 제안하는 방법론은 복잡한 질문을 효과적으로 생성할 뿐만 아니라 해당 질문을 복잡화하는 과정에서 생성된 중간 단계 질문들을 함께 제공한다. 따라서 질의응답 모델이 복잡한 질문을 논리적으로 추론할 수 있도록 하는 훈련 데이터를 생성하거나 교육용 문제 생성 등에 활용될 수 있다. 또한 복잡한 질문은 사람이 직접 오류를 판단하기 어려운데, 중간 단계에서 생성된 질문들의 오류를 조기에 판별함으로써 효과적으로 합성 데이터를 정제할 수 있다.
[연구결과의 진행 상태 및 향후 계획]
질문 생성 모델은 질의응답 데이터를 기반으로 훈련된다. 다만 대부분의 질의응답 데이터셋들이 영어로 구축되어 있기 때문에 다른 언어에서의 활용이 어렵다. 따라서 기존 영어 데이터셋으로 훈련된 질문 생성 모델을 다른 언어에 활용할 수 있도록 하는 Cross-lingual Transfer 방법론을 연구할 계획이다.
[성과와 관련된 실적]
Seonjeong Hwang, Yunsu Kim, and Gary Geunbae Lee, “Explainable Multi-hop Question Generation: An End-to-End Approach without Intermediate Question Labeling”, LREC-COLING 2024 (accepted)
[성과와 관련된 이미지]
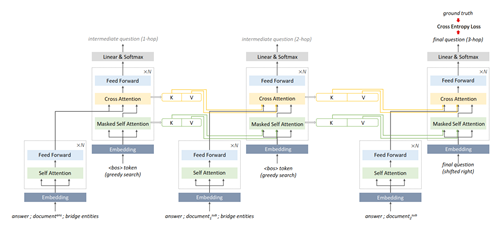
[그림 1] 3-hop 질문 생성을 위한 E2EQG 모델의 학습 과정

[그림2] E2EQR로 생성한 3-hop 질문 및 중간 단계 질문들의 예시