최신연구
[이근배 교수] Enhancing Zero-Shot Multi-Speaker TTS with Negated Speaker Representations
[연구의 필요성]
음성합성 기술의 발전으로 합성된 음성은 매우 자연스러워졌습니다. 이러한 발전으로 인해, 개인 맞춤형 음성합성 시스템에 대한 관심이 높아지고 있습니다. 특히, 특정 화자의 목소리로 음성을 합성하는 경우, 이는 미디어 측면 뿐만 아니라 고인의 목소리를 다시 듣게 해주는 기회로까지 이어지고 있습니다. 특정 화자의 목소리를 복제하기 위해서는 해당 화자의 목소리가 담긴 음성 파일들이 필요하며, 녹음된 오디오 파일로 음성합성 모델을 추가 학습해야 하는 경우가 많습니다(few-shot learning). 이러한 과정의 번거로움을 극복하기 위해 본 논문에서는 보다 효과적인 zero-shot 방법을 탐색하였습니다.
[포스텍이 가진 고유의 기술]
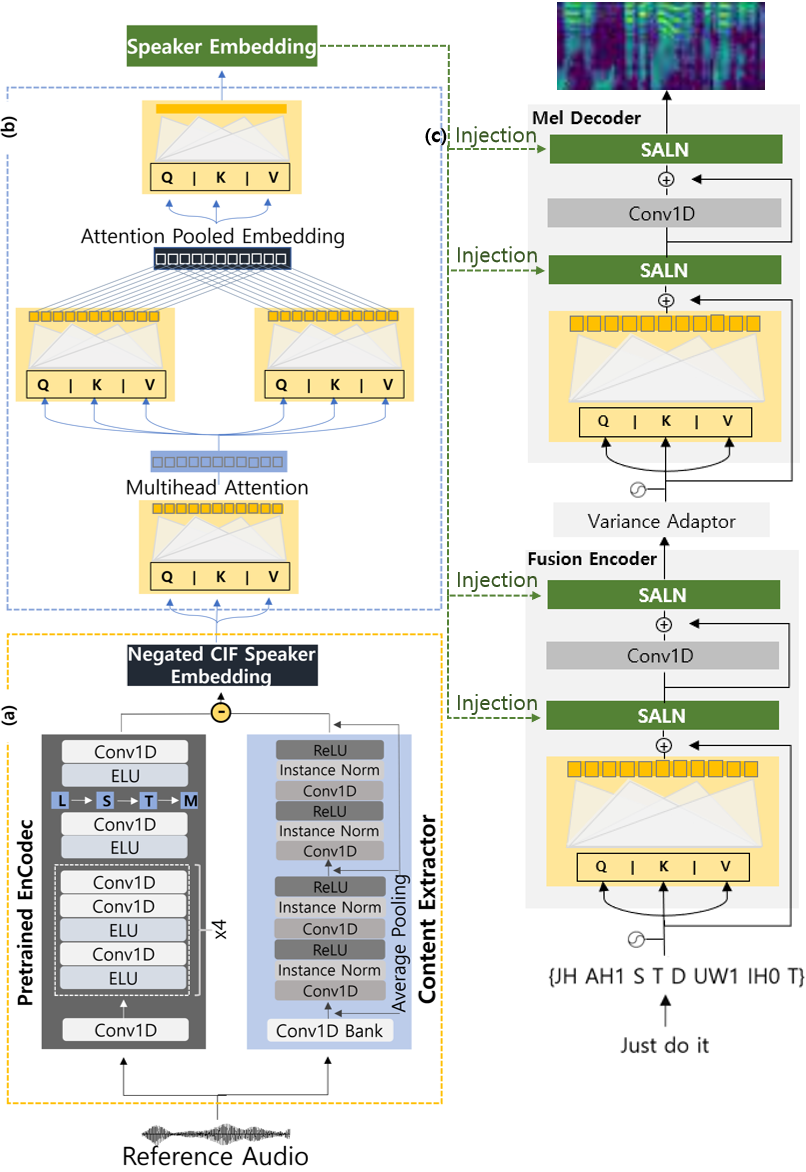
특정 화자의 목소리를 사용하여 음성을 합성하려면 음성합성 모델이 두 가지 입력값을 필요로 합니다. 첫째로, 텍스트 형식의 문장이며, 둘째로는 해당 화자가 직접 발화한 오디오 파일입니다. 그러나 오디오 파일에서는 화자의 발화 내용과 합성할 실제 텍스트 문장이 정확히 일치하지 않을 수 있기 때문에, 오디오 파일에서는 화자의 목소리 정보만을 추출해야 합니다. 일반적으로는 오디오 파일에서 화자의 목소리 정보를 바로 추출하고자 하는데, 이렇게 할 경우 언어적 특성이 목소리 정보에 포함될 수 있는 content leakage 문제가 발생합니다. 이를 해결하기 위해 본 연구에서는 오디오 자체를 embedding한 전역 표현에서 내용 정보를 추출한 임베딩을 빼는 subtractive한 방법을 제안하였습니다. 더불어, 특정 화자의 목소리를 보다 정확하게 추출하기 위해 multi-stream transformer를 활용하여 여러 개의 embedding을 사용하였고, 최종적으로 추출된 타겟 화자 목소리 representation을 adaptive 레이어를 통해 기본(backbone) 음성합성 모델에 통합함으로써 실제 화자의 목소리와 유사한 음성을 합성할 수 있었습니다.
[연구의 의미]
본 연구에서는 subtractive한 방법을 제안하였습니다. 제안된 방법론의 타당성을 검증하기 위해 다양한 메트릭을 활용하여 negation을 적용한 경우와 그렇지 않은 경우의 성능 차이, multi-stream Transformer의 활용 여부, 그리고 추출된 화자 목소리 representation을 backbone 음성합성 모델에 통합하는 위치와 횟수에 대한 실험을 진행하였습니다. 실험 결과, subtractive 방법을 통한 negated speaker representation을 사용하였을 때 특정 화자의 목소리로 원하는 텍스트 문장에 대한 음성 합성이 가능함을 확인할 수 있었습니다.
[연구결과의 진행 상태 및 향후 계획]
본 연구에서는 특정 화자의 목소리를 따라하기 위해 오디오 입력을 사용했다면, 앞으로는 다른 모달리티(modality)의 입력을 활용하여 음성을 합성할 수 있도록 연구를 확장할 계획입니다.
[성과와 관련된 실적]
Yejin Jeon, Yunsu Kim, Gary Geunbae Lee, “Enhancing Zero-Shot Multi-Speaker TTS with Negated Speaker Representations”, AAAI 2024 Accepted
[성과와 관련된 이미지]