최신연구
[이근배 교수] Autoregressive Multi-trait Essay Scoring via Reinforcement Learning with Scoring-aware Multiple Rewards
[연구의 필요성]
최근 자동 작문 채점 기술 (Automated Essay Scoring; AES)은 단일 특성을 평가하는 것에서 벗어나 다양한 특성을 평가하여 보다 풍부한 피드백을 제공하는 Multi-trait AES 기술로 나아가고 있다. Multi-trait AES 시스템의 성능은, 단일 AES와 마찬가지로 모델 예측 점수와 인간 채점자와의 동의도를 평가하는 QWK를 기준으로 평가되지만, 미분 불가능성으로 인해 딥러닝 기반 모델 학습에 직접적으로 사용되지 못하였다. 본 연구에서는, 실제 채점 체계를 반영하지 못하는 기존의 단순 오차율 기반 회귀 학습법에서 벗어나, 등급 체계를 고려할 수 있는 평가 지표를 모델 학습에 직접적으로 활용하고자 한다.
[포스텍이 가진 고유의 기술]
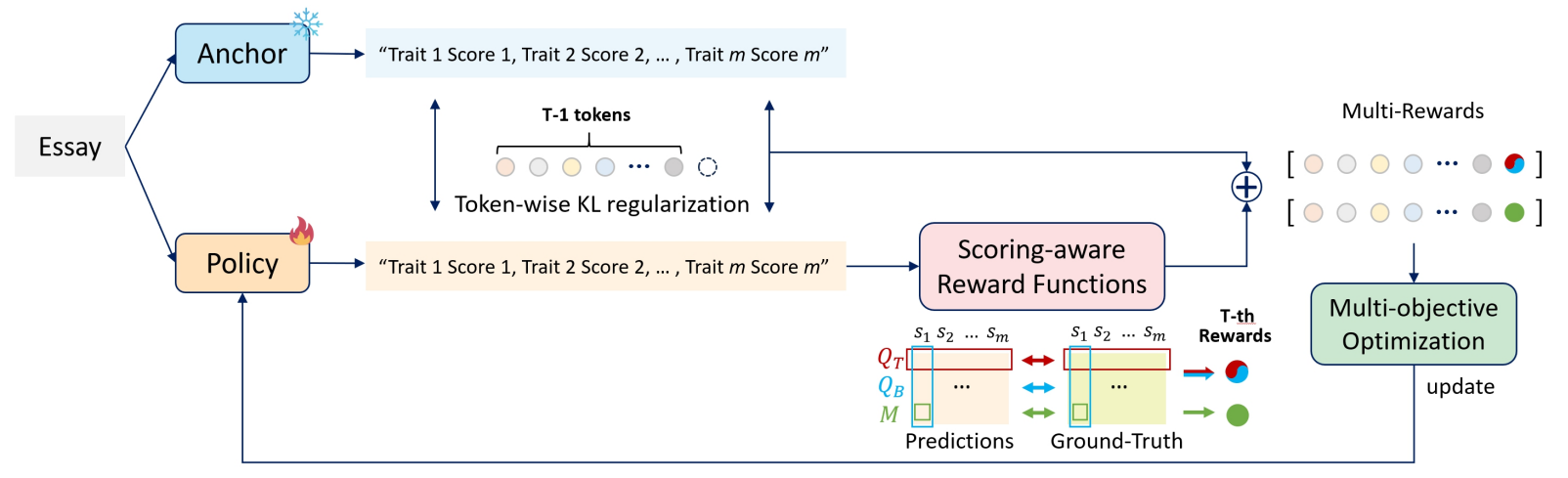
본 연구에서는 Multi-trait AES 시스템의 질을 향상시키기 위해 채점 체계를 반영한 다중 보상 강화학습 (Scoring-aware Multi-reward Reinforcement Learning; SaMRL)을 제안한다. 양방향 QWK 기반 리워드와 MSE 기반 패널티의 다중 리워드를 설계하여 평가 체계를 학습 과정에서 반영하도록 한다. 또한, 넓은 범위의 점수 예측에 취약하던 기존의 분류 (classification) 방식의 강화학습 도입 방법론 대신 자동 회귀 (autoregressive) 점수 생성 프레임워크를 기반으로 강화학습을 도입하여 토큰 생성 확률을 활용함으로써 다양하고 넓은 범위의 다중 특성 점수 예측 성능을 향상시킨다.
[연구의 의미]
제안된 방법은, AES를 생성 문제로 접근하여, MSE나 QWK와 같은 채점 관련 지표들이 전혀 고려되지 못하여 불안정했던 문제를 보완함으로써 다측면에서 성능 향상을 보였다. 또한, 강화 학습을 적용하기 위해 분류 문제로 접근했던 기존 모델에서 점수 범위가 넓은 경우 성능이 급격히 저하되던 문제도 동시에 해결하였다. 분류 기반 접근법들의 한계로 인해 많이 탐구되지 못했던 AES에서의 강화학습을 생성 문제로 전환함으로써 다측면에서 자동 채점의 질을 개선하며 분야의 발전에 기여하였다.
[연구결과의 진행 상태 및 향후 계획]
현재는 Multi-trait 점수를 예측함에 있어서 데이터 수가 많은 측면에서 적은 측면으로 순차적으로 예측하는 방법을 도입하였다. 추후에는 예측 순서의 변화를 주는 것에 대해 추가적인 고려를 할 생각이다. 또한, 현재는 전체 trait 예측이 끝난 시점에서 policy를 한번에 업데이트 하지만, 향후 각 action 마다 업데이트를 함으로써 policy를 학습하는 방법론을 도입하고자 한다.
[성과와 관련된 실적]
본 연구는 자연어 처리 분야의 EMNLP 2024 학회에서 발표될 예정이다.
[성과와 관련된 이미지]