최신연구
[곽수하 교수] Learning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval
[연구의 필요성]
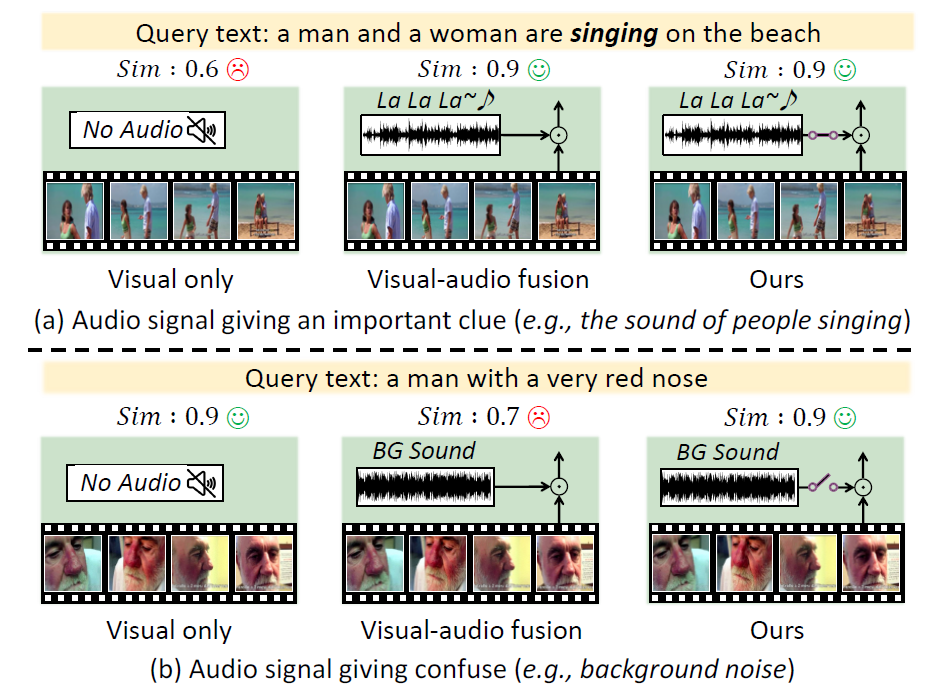
기존 영상-텍스트 검색(Video-Text Retrieval) 모델은 주로 영상의 시각 정보와 텍스트 정보만을 활용하여 영상 콘텐츠를 이해하고 검색해왔음. 그러나 영상에는 시각 정보 외에도 풍부한 오디오 정보가 존재하며, 이는 인물의 감정, 배경 상황, 발화 내용 등 ‘보이지 않지만 들리는’ 중요한 단서를 제공할 수 있음. 기존 방법들은 이러한 오디오 정보를 무분별하게 활용하거나 아예 무시하는 경향이 있어, 오히려 관련없는 오디오(예: 배경 소음)가 검색 성능을 저해하는 문제가 있었음.
[포스텍이 가진 고유의 기술]
포스텍 연구팀은 오디오의 유용성을 동적으로 판단하여 시각 정보와 선택적으로 융합할 수 있는 Gated Attention 기반의 융합 모듈을 개발함. 또한, 시청각 표현과 텍스트 간의 정밀한 정렬을 위해 intra-modal 유사도를 고려한 적응형 margin 기반의 대조 손실함수를 개발함.
[연구의 의미]
본 연구는 영상-텍스트 검색 분야에서 오디오 정보를 효과적으로 통합하는 방법론을 제안함으로써, 기존 시각 중심 모델들의 한계를 극복하였음.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 뛰어난 성과를 인정받아 컴퓨터 비전 최고 수준 학회인 CVPR 2025에 구두(Oral)로 발표 예정임.
[성과와 관련된 실적]
Boseung Jeong, Jicheol Park, Sungyeon Kim, Suha Kwak. “Learning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval”. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
[성과와 관련된 이미지]