최신연구
[박은혁 교수] OWQ: Outlier-Aware Weight Quantization for Efficient Fine-Tuning and Inference of Large Language Models
[연구의 필요성]
대규모 언어 모델 (Large language models, LLM)은 큰 모델 크기와 학습 데이터를 바탕으로 문장 생성 및 다양한 분야에서 뛰어난 성능을 보이고 있다. 하지만 거대 모델의 큰 메모리 요구량으로 인해 미세 조정 (fine-tuning) 및 추론 (inference) 에 서버 규모 GPU 여러 장을 필요로 한다는 문제가 있다. 이런 문제를 해결하기 위해 모델 가중치의 비트 수를 낮추는 가중치 양자화 (weight quantization) 가 사용되지만, 이 때 표현 가능한 숫자 범위 또한 줄어들어 모델 추론 성능이 감소하는 문제가 존재한다. 본 연구의 결과물을 활용하면 대규모 언어 모델의 성능을 유지하면서 서비스에 필요한 GPU의 요구량을 크게 줄일 수 있다.
[포스텍이 가진 고유의 기술]
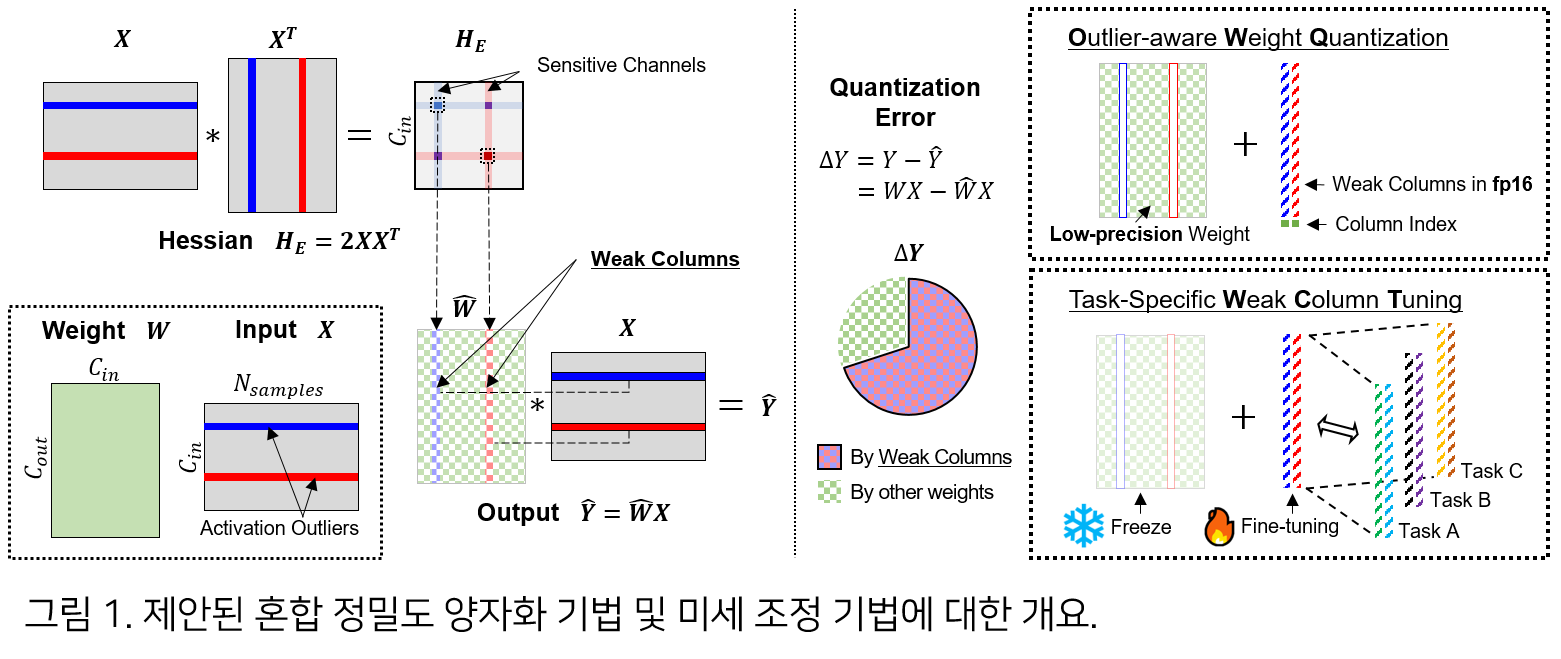
대규모 언어 모델에 양자화를 적용할 시 성능이 감소하는 주요 원인은 활성화 값 (activation) 의 특정 채널에서 절대값이 매우 큰 이상치 (outlier) 가 발생하기 때문이다. 본 연구에서는 위 특성을 고려하여 활성화 이상치에 대한 가중치의 민감도를 정의하고 이를 기반으로 민감한 가중치는 높은 정밀도로 유지하는 혼합 정밀도 양자화 (mixed-precision quantization) 방법을 제안하였다. 우리의 방법은 최적화된 GPU 혼합 정밀도 연산 커널을 개발하여 기존의 방법에 비해서 매우 적은 오버헤드로 크게 향상된 성능을 보인다. 또한 양자화 후 높은 정밀도로 유지한 가중치만 조정하는 효율적인 미세 조정 기법을 제안하였고 기존 방법들에 비해 더 적은 학습 파라미터를 이용해 유사한 성능으로 조정됨을 보였다.
[연구의 의미]
본 연구에서는 모델 가중치 양자화 시 낮은 비트 수의 장점을 유지하면서 원래 모델의 성능을 거의 보존하는 새로운 경량화 방법을 제안하였다. 그 과정에서 활성화 값 이상치가 가중치 양자화에 중요한 영향을 미침을 보였다. 아울러 해당 양자화 기법을 활용하여 미세 조정 시 메모리 사용량을 크게 줄이는 효율적인 조정 방법을 제안하였다. 이를 통해 메모리 용량이 제한된 일반 사용자용 GPU 등에서도 대규모 언어 모델의 추론 및 미세 조정이 가능하게 되어 언어 모델의 활용 및 연구의 장벽을 낮춘 것이 가장 큰 의미이다.
[연구결과의 진행 상태 및 향후 계획]
본 연구는 인공지능 분야 최우수 국제학술대회인 Association for the Advancement of Artificial Intelligence (AAAI) 2024에서 포스터로 발표될 예정이다. 향후 대규모 언어 모델의 효율적인 학습 및 실제 서비스를 낮은 비용으로 제공하기 위한 최적화 연구를 계획 중이다.
[성과와 관련된 실적]
Changhun Lee*, Jungyu Jin*, Taesu Kim, Hyungjun Kim, Eunhyeok Park, “OWQ: Outlier-Aware Weight Quantization for Efficient Fine-Tuning and Inference of Large Language Models”, AAAI 2024
[성과와 관련된 이미지]